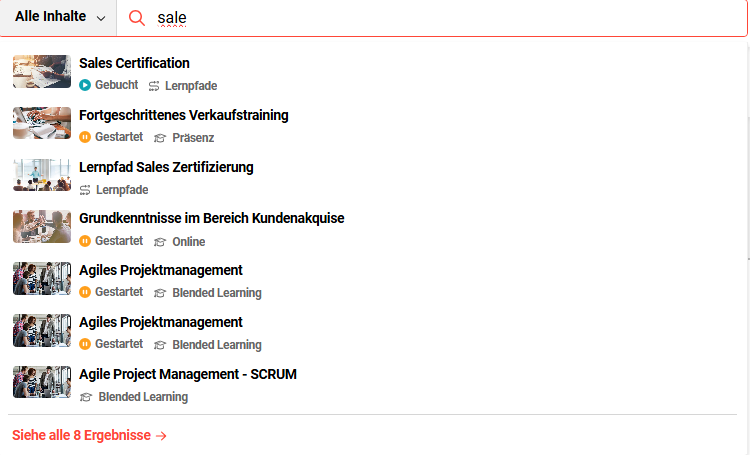
Die globale Suche steht allen Kunden mit Kubernetes zur Verfügung.
Übersicht und Funktionen
Die globale Suche hilft den Benutzern dabei, Lerninhalte über Kataloge, Channels (sofern das Add-on genutzt wird) und persönliche Lerninhalte mit einem Lernstatus (Mein Lernbereich) hinweg zu finden.
Weitere Informationen dazu, was genau gefunden und als Ergebnisse angezeigt wird, finden Sie hier: Datenkonnektor
Die Inhaltssuche durchsucht Titel, Beschreibungen und (bei der lexikalischen Suche zusätzlich) die Stichwörter von Channelmedien, Kursen, Kursvorlagen, Lernpfaden und Lernpfadvorlagen.
Bitte überprüfen Sie die Liste der Sprachanalysatoren um herauszufinden, welche Sprachen von Elasticsearch unterstützt werden. Sollte Ihre Sprache nicht in der Liste aufgeführt sein, wenden Sie sich bitte an Scheer IMC, um nach Möglichkeiten zu fragen.
Ausgelöst durch die Suchanfrage des Nutzers findet die Suche Inhaltsobjekte und ordnet sie nach ihrer Relevanz. Es gibt zwei Möglichkeiten, die Relevanz zu bestimmen: a) lexikalische Suche (Standardeinstellung, ohne KI) und b) semantische Suche (auf Anfrage, KI-gestützt).
Zwei Sucharten: lexikalische vs. semantische Suche
Die globale Inhaltssuche wird standardmäßig allen Kunden mit der Produktversion 14.25.1 und höher bereitgestellt. Administratoren können entscheiden, ob sie für Benutzer sichtbar sein soll oder verborgen bleibt.
Standardmäßig wird die lexikalische Suche verwendet.
Lexikalische Suche
Die Wörter in der Suchanfrage des Nutzers werden mit Titeln, Stichwörtern, benutzerdefinierten IDs (Identifikationscodes) und Beschreibungen der indexierten Inhalte abgeglichen. Bei dieser Methode kommt keine KI zum Einsatz.
Textvorverarbeitung
-
Tokenisierung (teilt Text in einzelne Einheiten (Token) auf, in der Regel Wörter oder Wortteile)
-
In Kleinbuchstaben umwandeln (wandelt den gesamten Text in Kleinbuchstaben um, damit die Groß- und Kleinschreibung keinen Einfluss auf den Abgleich hat)
-
Entfernen von Stoppwörtern (entfernt häufig vorkommende Wörter mit geringem Unterscheidungswert (z. B. „und“, „der“…)
-
Stammbildung (reduziert Wörter auf einen gemeinsamen Stamm, damit verschiedene grammatikalische Formen miteinander übereinstimmen können)
Analysemethoden
-
Stammwortbasierte Suche reduziert Wörter auf eine gemeinsame sprachliche Wurzel (Stamm), sodass bei der Suche verschiedene grammatikalische Formen desselben Wortes einander zugeordnet werden.
Vorteil: Die Suche findet nicht nur „running“, sondern auch „run“ oder „ran“ -
Edge-n-Gram-Suche (unterstützt ab Produktversion 14.27.0.0)
Ein Edge-n-Gramm ist eine Zeichenfolge der Länge „n“, die vom Anfang (Edge) eines Wortes gebildet wird. Beispiel: Wort: „search“ => 3-Gramm: „sea“, 4-Gramm: „sear“, 5-Gramm: „searc“….
Der Text wird als Wortpräfixe indexiert, und Suchanfragen der Nutzer werden anhand dieser Präfixe bzw. Fragmente abgeglichen, nicht anhand der vollständigen Wörter. Die Edge-n-Gram-Suche wird nur auf Titel und Beschreibung angewendet. Bei Schlüsselwörtern, die Sie dem Inhalt zugewiesen haben, gilt nur das vollständige Schlüsselwort als Übereinstimmung. (Das Schlüsselwort „Win10“ stimmt nicht mit der Suchanfrage „Win100“ überein.)Vorteile:
-
Die Ergebnisse werden angezeigt, noch bevor ein Wort vollständig (bis zum Wortstamm) eingegeben wurde; N-Gramme schließen somit Lücken bei unvollständigen Eingaben
-
Bei Suchanfragen, die eine Abkürzung enthalten (wie „LMS“), lassen sich zwar weder Wortstämme noch Wortbedeutungen ableiten, doch Edge-n-Gramme ermöglichen einen teilweisen und toleranten Abgleich. Dies ist ideal für die „Search-as-you-type“-Funktion.
-
-
Unscharfe Suche (deaktiviert (für Produktversion ≥ 14.27.1.0)
Die Fuzzy-Suche findet Wörter, die sich in der Schreibweise ähneln, auch wenn es sich um unterschiedliche Wörter handelt.
Diese Funktion war bis zur Produktversion 14.27.0.0 aktiviert, da sie eine größere Toleranz gegenüber Rechtschreibfehlern bot. Die Erfahrungen der Kunden haben jedoch gezeigt, dass sie die Ergebnisliste überfrachtet und zu viele irrelevante Ergebnisse liefert. Mit IP 14.27.1.0 ist sie daher deaktiviert.
Eine lexikalische Suche wird empfohlen, wenn…
-
Ihre Nutzer suchen hauptsächlich nach einem oder wenigen Stichwörtern
-
Ihre Nutzer suchen häufig nach bestimmten Begriffen, Abkürzungen oder Zahlen
-
Ihre Nutzer erwarten, dass sie das genau Formulierung ihrer Suchanfrage in den obersten Ergebnissen (Titeln)
Semantische Suche
Die semantische Suche nutzt KI-gestützte Technologie, um die Absicht und Bedeutung hinter Nutzeranfragen sowie den Inhalt der indexierten Daten (derzeit: Titel und Beschreibung) zu interpretieren. Sie versteht natürliche Sprache und vergleicht die semantische Bedeutung der Anfrage mit der der Lerninhalte. Auf diese Weise kann sie die relevantesten oder am ehesten passenden Informationen abrufen – selbst wenn unterschiedliche Formulierungen, Ausdrücke, Synonyme oder Schreibweisen verwendet werden.
Diese Funktion basiert auf KI-Diensten von Scheer IMC, darunter ein Embedding-Dienst, der sowohl die indexierten Inhalte als auch jede Nutzeranfrage vektorisiert. Siehe https://doc-en.scheer-imc.com/FuncRef/ai-enhanced-content-search#Switch-to-AI-enhanced-semantic-search weitere Informationen dazu, wie Sie die semantische Suche aktivieren können.
So funktioniert die semantische Suche:
-
Mithilfe von Modellen der natürlichen Sprachverarbeitung (NLP) und des maschinellen Lernens wird Text in Vektoren umgewandelt, die die Bedeutung wiedergeben.
-
Die Ähnlichkeit der Vektoren zwischen der Benutzeranfrage und den indizierten Dokumenten wird verglichen, um die relevantesten Ergebnisse zu ermitteln.
-
Für die Vektordarstellungen, auch als Text-Embeddings bezeichnet, nutzt imc ein selbst gehostetes Embedding-Modell (jeffh), das von Ollama betrieben wird.
Eine semantische Suche empfiehlt sich, wenn…
-
Ihre Nutzer suchen häufig nach bestimmten Themenbereichen und möchten auch eng damit verbundene Inhalte finden
-
Ihre Nutzer haben manchmal Schwierigkeiten, genau den Suchbegriff zu finden, der mit der Formulierung übereinstimmt, die die Autoren im Titel verwenden.
-
Ihre Suchanfragen und Ihre Inhalte bieten genügend Kontext, damit die semantische Suche „arbeiten“ kann. Ihre Kurs-, Lernpfad- und Medienbeschreibungen sind gut gepflegt und ergänzen den Titel um Hintergrundinformationen. Je mehr Eingaben und Kontext vorhanden sind, desto besser funktioniert die semantische Suche. Je mehr Informationen Sie bereitstellen, desto besser kann die semantische Suche die Bedeutung interpretieren. Nutzer können die Relevanz der Ergebnisse weiter verbessern, indem sie Fragen stellen, anstatt nur einen einzigen Suchbegriff zu verwenden.
Wenn Sie daran interessiert sind, die semantische Suche mit aktivierten KI-Diensten zu nutzen, lesen Sie bitte diesen Text https://doc-en.scheer-imc.com/GettingStarted/ai-enhanced-content-search-compliance-information .
Zusammenfassend lässt sich sagen:
Wenn Nutzer exakte Übereinstimmungen auf der Grundlage der Zeichen wünschen, die sie in ihre Suchanfrage eingeben, ist die lexikalische Suche die richtige Wahl; wenn sie möchten, dass das System den Sinn versteht und Abweichungen in der Formulierung toleriert, ist die semantische Suche die bessere Option.
Merkmale und Vorteile
-
Zentrale Anlaufstelle für Inhalte
Die globale Suche ist von überall im System aus zugänglich, da sie sich in der oberen Navigationsleiste befindet. Die Navigationssuche (die hauptsächlich von Administratoren genutzt wird) ist nun hinter einem eigenen Symbol zu finden. Auf dem Screenshot sehen Sie sie neben dem Einstellungsrad.
-
Erweiterter Umfang: Suche in allen Katalogen, den Channelsn und (ab Version 14.27.1) auch in „Mein Lernbereich“
Kunden mit mehreren Inhaltsquellen profitieren von einer umfassenden Suche über verschiedene Bereiche hinweg: alle Kataloge, Channels (Add-on) und Inhalte mit einem persönlichen Lernstatus (Mein Lernbereich), die möglicherweise keinem Katalog zugeordnet sind. Mit dem Filter „Inhaltsbereich“ können Benutzer entscheiden, ob sie in allen oder nur in ausgewählten Bereichen suchen möchten. Der Filter „Inhaltsbereich“ wird nur für Benutzer angezeigt, die Zugriff auf mehr als eine Datenquelle haben. -
Weniger Klicks für einen schnelleren Zugriff auf Inhalte
Sobald Nutzer mit der Eingabe beginnen, werden die sieben besten Ergebnisse in einer Ebene angezeigt. So können Nutzer auf die besten Ergebnisse zugreifen, ohne zu einer Suchergebnisseite navigieren zu müssen. -
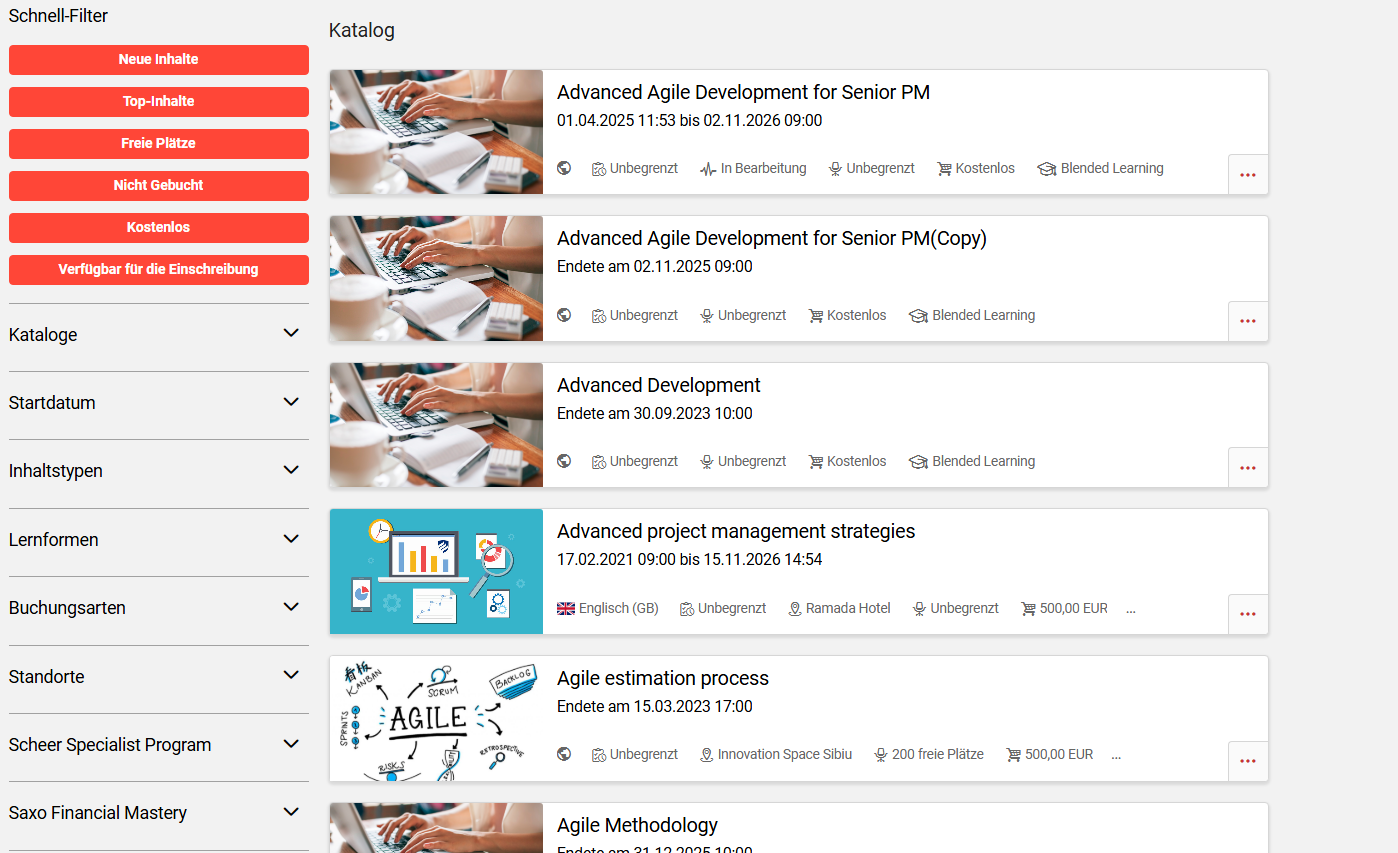
Erweiterte Suche
Wenn Nutzer alle Ergebnisse anzeigen möchten, können sie über den Link „Alle Ergebnisse anzeigen“ zur erweiterten Suche wechseln oder die Eingabetaste drücken. Auf der Seite der erweiterten Suche können Nutzer Filter anwenden und die Ergebnisse anhand ihrer Beschreibungen und weiterer Kriterien vergleichen. -
Neue, hochmoderne Suchtechnologie
ElasticSearch ist eine leistungsstarke, skalierbare und leistungsfähige Suchmaschine, die mehrere Sprachen unterstützt und zahlreiche Möglichkeiten bietet, die Relevanz zu steigern und personalisierte Ergebnisse zu liefern.
Die Suche wird weiter verbessert und bildet die Grundlage für weitere KI-Funktionen wie den Lernassistenten.
Weitere Suchanfragen im System
-
Bereits vorhandene Suchleisten, wie sie in den Katalogen, im Bereich „Mein Lernbereich“ oder auf den Übersichtsseiten zu finden sind, sind von der globalen Suche nicht betroffen. Sie basieren auf einer anderen Technologie, suchen nur innerhalb einer Seite oder eines Bereichs und werden nicht durch die globale Suche ersetzt, sondern können parallel dazu bestehen bleiben.
-
Nutzer, die auf eine überwältigende Anzahl von Zugriffspunkten auf Inhalte zugreifen, profitieren von einem vereinfachten Zugriff über eine zentrale globale Suchleiste.
-
Bitte beachten Sie: Die Navigationssuche (hauptsächlich für Administratoren), die sich bisher in der oberen Navigationsleiste befand, bleibt dort erhalten, ist jedoch hinter einem neuen Symbol zu finden:
Konfiguration und Einstellungen
Erste Schritte
Die globale Suche ist ab Version ≥14.25.1.0 im Standardprodukt enthalten und wird als lexikalische Suche . Dies schließt jegliche KI aus.
Sichtbarkeit und Zugriff auf die Suchleiste über einen Navigationspunkt aktivieren
-
Damit die Suche in der oberen Navigationsleiste angezeigt wird, müssen Sie den Navigationspunkt für Ihre Benutzergruppen konfigurieren.
-
Gehen Sie zu „Navigation“ und suchen Sie nach „Platformweite Suche“, um die Zugriffsrechte zu bearbeiten.
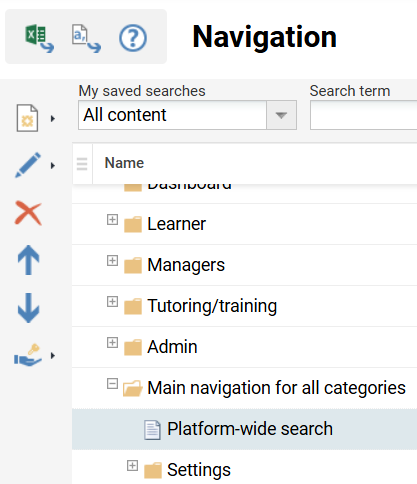
Zugriff auf die Suchkonfigurationen
-
Um Ihren Administratoren Zugriff auf die Sucheinstellungen und die Konfiguration des Datenkonnektors zu gewähren, gehen Sie zu „Navigation“ und suchen Sie nach „data_connector_configuration“.
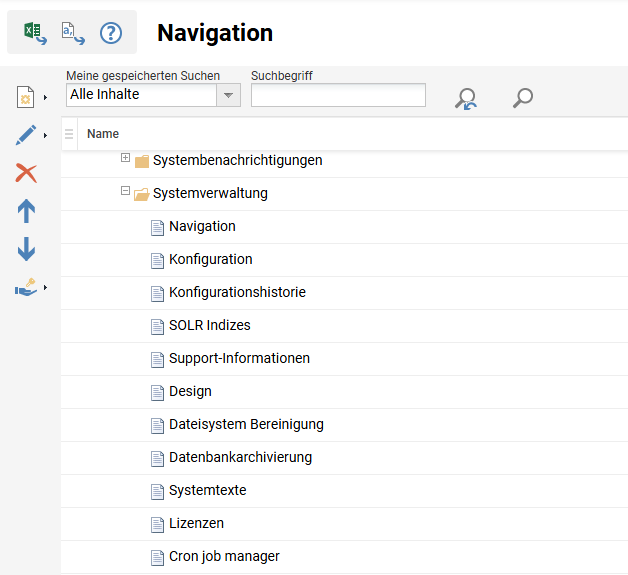
Weitere Informationen finden Sie hier.
Melden Sie sich nach diesen Änderungen ab und wieder an.
Datenkonnektoren konfigurieren
imc nutzt einen Plugin-Ansatz, bei dem jedes Plugin einen anderen Bereich von Lerninhalten repräsentiert, der indexiert wird, damit Nutzer Inhalte aus dieser Quelle finden können. Die Plugins können vom Data Connector ausgeführt werden, entweder zeitgesteuert (als wiederkehrende oder einmalige Aufgaben) oder ad hoc.
Lerninhalte sind erst nach einem erfolgreichen ersten Durchlauf durchsuchbar. Der erste Durchlauf sollte eine vollständige Synchronisierung sein, während bei jedem weiteren Durchlauf neue oder aktualisierte Inhalte zum Suchindex hinzugefügt werden. Eine Indizierung in Echtzeit wird derzeit noch nicht unterstützt, wir planen jedoch, diese Funktion in Zukunft zu aktivieren.
In der Konfiguration des Datenkonnektors können Administratoren
-
Daten-Plugins zum Repository hinzufügen oder daraus entfernen
-
diese Daten-Plugins konfigurieren
-
Cron-Jobs planen und verwalten, um den Suchindex mit ihren Daten zu synchronisieren.
-
einen sofortigen Synchronisierungsauftrag unabhängig vom Zeitplan ausführen
Die Daten-Plugins, mit denen Sie Ihre Kataloge, Channels und Ihren persönlichen Lernstatus durchsuchen können, sind bereits standardmäßig hinzugefügt. Außerdem sind standardmäßig Jobs so geplant, dass sie täglich nachts ausgeführt werden. Sie können einen Job sofort auslösen, ohne Ihren regulären Zeitplan zu ändern, indem Sie auf die Schaltfläche „Abspielen“/„Jetzt ausführen“ klicken.
Bitte befolgen Sie diese Anweisungen, um die Plugins zu konfigurieren: Datenkonnektor .
Jobs definieren und überprüfen
Für jeden hier aufgeführten Auftrag können Sie einen bestimmten Zeitplan festlegen. Verwenden Sie die Menüschaltfläche mit den drei Punkten auf der rechten Seite (bei Mouse-Over), um die Aufträge zu bearbeiten.
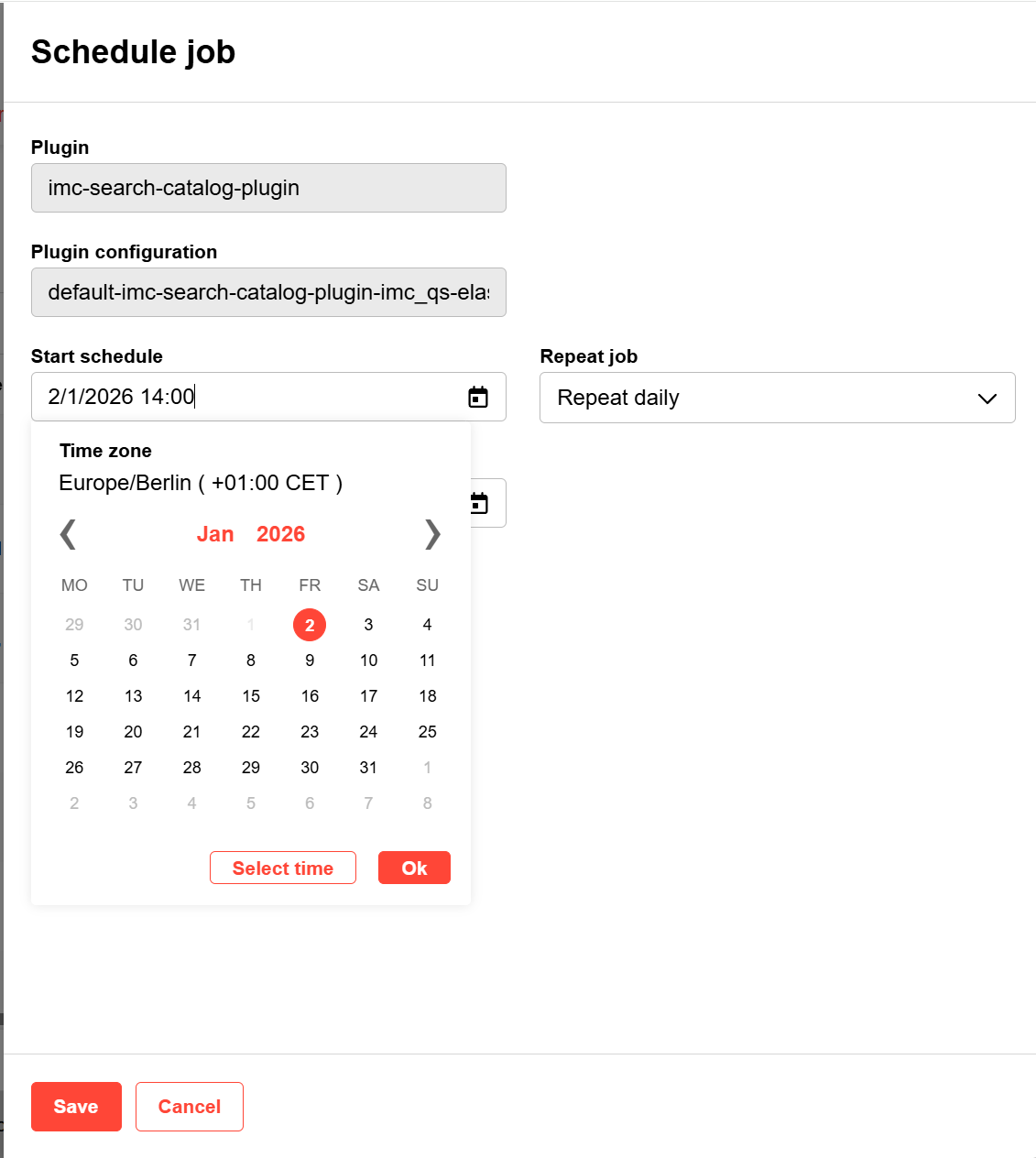
Die Spalten auf dieser Seite enthalten folgende Informationen:
Job: Name des Jobs, der den Suchindex mit Ihren Daten synchronisiert
Konfiguration: Name der Konfiguration des Auftrags
Plugin: Name des Plugins, das eine verbundene Datenquelle repräsentiert (z. B. Channels, Kataloge oder „Kontext“, d. h. Inhalte aus „Mein Lernbereich“)
Letzte Ausführung: Zeigt Datum und Uhrzeit des letzten Auftragsendes an
Aktueller Stand: zeigt den Status des zuletzt ausgeführten Auftrags an
Zeitplan aktivieren: Wenn Sie für einen zukünftigen Auftrag (wiederkehrend oder einmalig) ein Datum und eine Uhrzeit festlegen, wird der Zeitplan automatisch aktiviert; Sie können ihn jedoch manuell deaktivieren, falls Sie den festgelegten Zeitplan unterbrechen möchten.
Wiederkehrend: Zeigt an, ob der Job in festgelegten Abständen immer zur festgelegten Zeit ausgeführt wird („Ja“) oder ob er nur einmal ausgeführt wurde („Nein“)
Nächster Ausführungszeitpunkt: Zeigt Datum und Uhrzeit an, zu der der nächste Auftrag startet. Ist das Feld leer, ist kein zukünftiger Auftrag geplant.
Bitte beachten Sie: Sollte der Vorgang für das Channel-Plugin fehlschlagen, liegt das Problem möglicherweise an Datenkonnektor (siehe das blaue Infofeld). Sollte ein Auftrag fehlschlagen, können Sie die Protokolldateien herunterladen, um zu überprüfen, was schiefgelaufen ist.
Optionale Schritte
Wechseln Sie zur KI-gestützten semantischen Suche
Wenn Sie aktivieren möchten semantische Suche Damit Ihre Nutzer davon profitieren können, muss imc Ihnen KI-Dienste zur Verfügung stellen.
-
Bevor Sie sich für eine KI-gestützte, semantische Suche entscheiden, vergewissern Sie sich bitte, dass Sie die https://doc-en.scheer-imc.com/GettingStarted/ai-enhanced-content-search-compliance-information
-
Bitte wenden Sie sich an den Scheer IMC-Service-Helpdesk, um die Bereitstellung dieser Dienste ohne zusätzliche Kosten zu beantragen.
-
Sobald die Dienste verfügbar sind, können Sie die semantische Suche in den Sucheinstellungen aktivieren.
Gehen Sie zu „Konfiguration“ > „Sucheinstellungen“, 2. Registerkarte „Globale Suche“ und stellen Sie den „Aktiven Suchtyp“ auf „Semantische Suche“ um.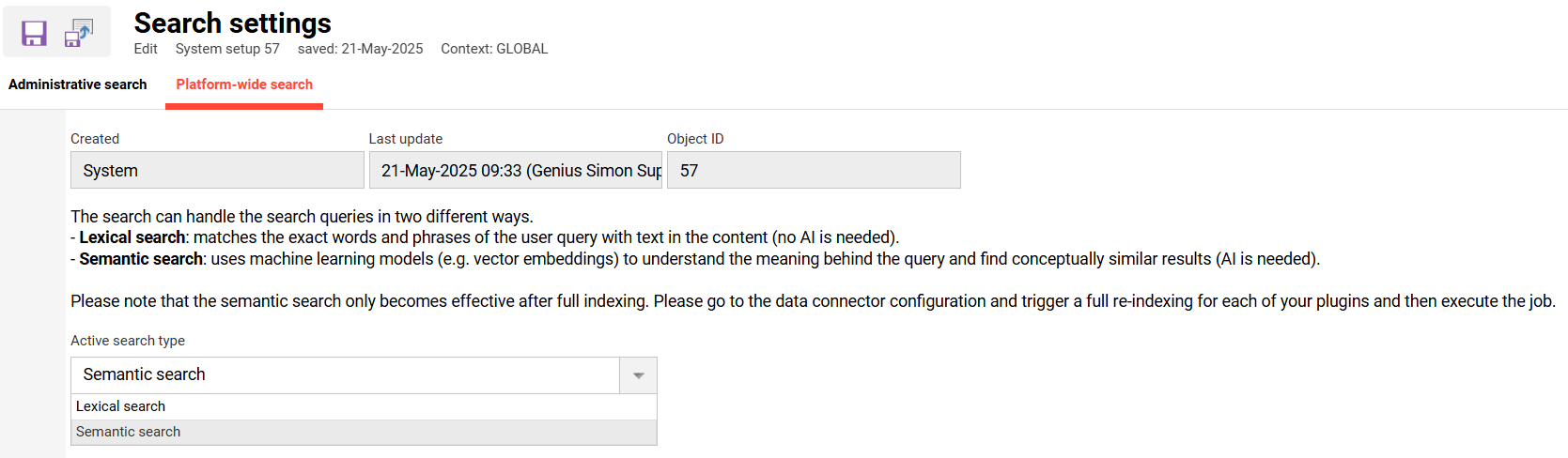
-
Bitte beachten Sie: Für einen Schalter ist ein weiterer erforderlich vollständige Indizierung Ihrer Daten. Der Einbettungsdienst muss für alle Inhalte Vektoren erstellen, um deren Bedeutung besser interpretieren zu können.
-
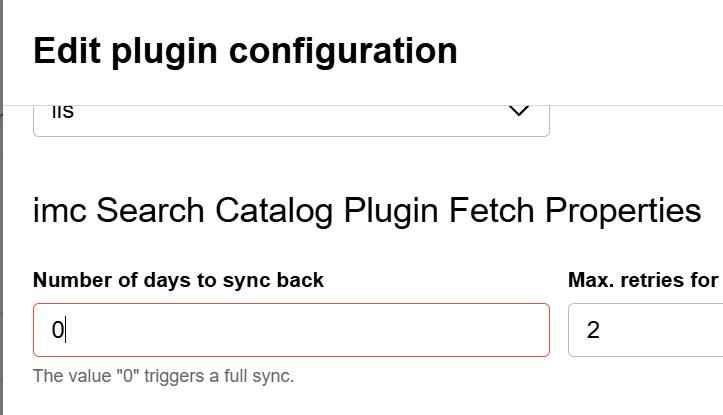
Rufen Sie die Konfiguration des Datenkonnektors auf, um eine vollständige Synchronisierung des Suchindexes beim nächsten Job anzufordern.
-
Gehen Sie in der Konfiguration des Datenkonnektors auf die zweite Registerkarte „Konfigurationen“, suchen Sie nach „Eigenschaften zum Abrufen des Katalog-Plugins“ und geben Sie eine „0“ in das Feld „Synchronisierungszeitraum (Anzahl Tage, rückwirkend)“.
-
Wir empfehlen, diese vollständige Synchronisierung außerhalb der Arbeitszeiten durchzuführen, da sie (je nach Datenvolumen) einige Zeit in Anspruch nehmen kann und bei gleichzeitigen Suchanfragen das Sucherlebnis der Benutzer beeinträchtigen könnte. Wir empfehlen außerdem, die Einstellung „0“ für zukünftige Synchronisierungen wieder auf den von Ihnen bevorzugten Zeitraum zurückzusetzen, da eine vollständige Synchronisierung danach möglicherweise nicht jedes Mal erforderlich ist.
-
Siehe Konfigurationsmanager – Sucheinstellungen
Weitere Informationen finden Sie hier.
Sollten Sie Ihre Entscheidung bezüglich der Suchart aus irgendeinem Grund rückgängig machen wollen, können Sie in den Sucheinstellungen wieder zur lexikalischen Suche zurückkehren.
Den Wortlaut der Benutzeroberfläche anpassen
Möglicherweise haben Sie für „Katalog“, „Channels“ oder „Mein Lernbereich“ eigene Unternehmensbezeichnungen gewählt.
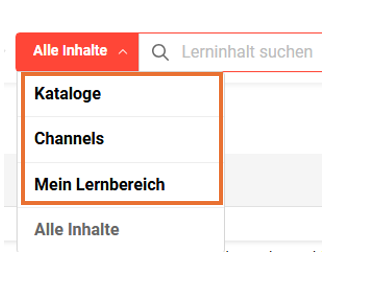
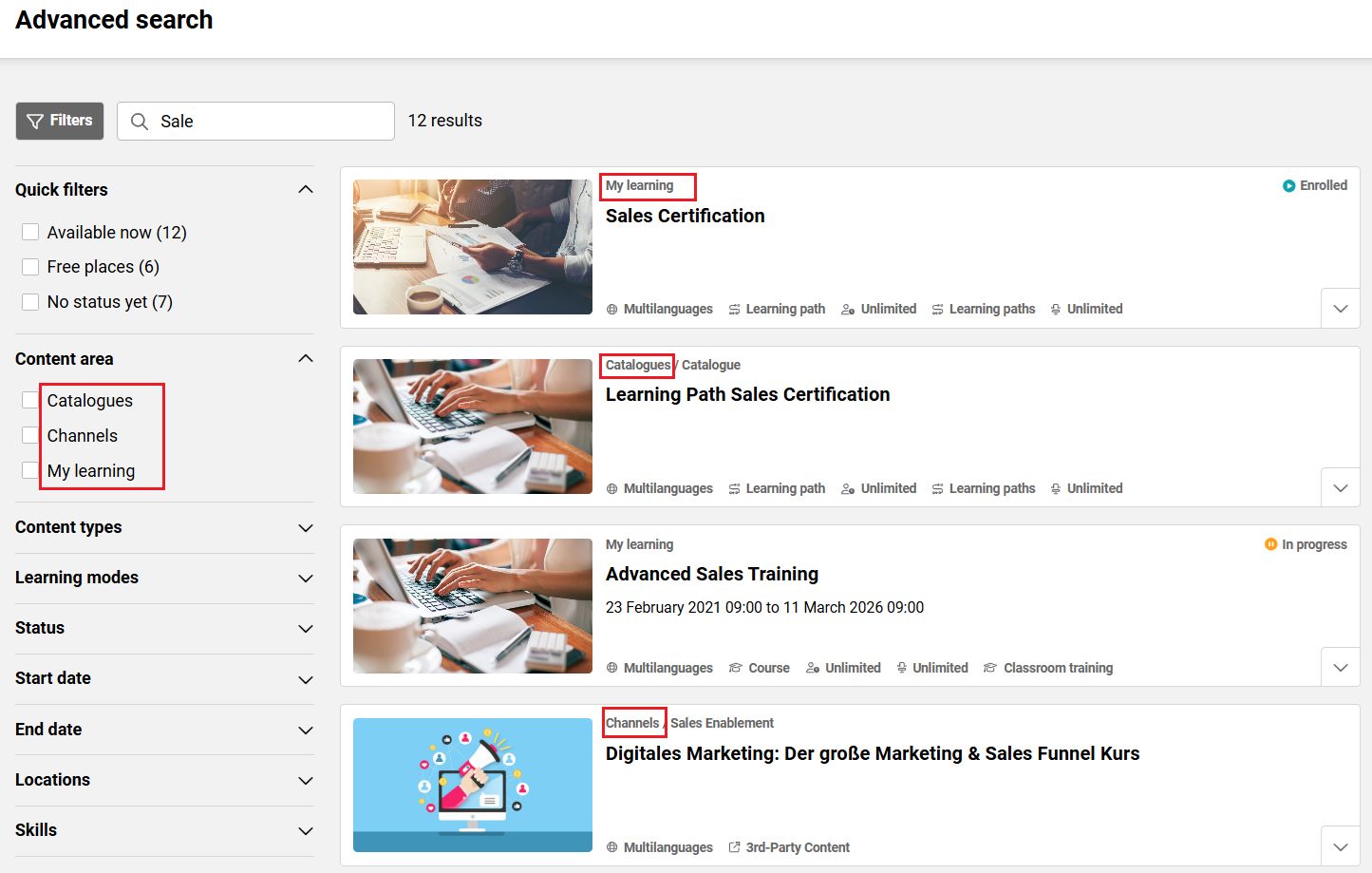
Falls Ihre Benutzer mit den Standardbegriffen, die imc in der Suchoberfläche verwendet, nicht vertraut sind, weil Sie diese in Ihrem System anders bezeichnen (z. B. „Lernangebot“), können Sie die Bezeichnungen im „Systemtexte“.
Im Folgenden finden Sie die Namen der Bundles für „Katalog“, „Channels“, „Kursvorlagen“ und „Mein Lernbereich“, die entsprechend den individuellen Bezeichnungen angepasst werden können. Bitte beachten Sie, dass diese Bundles speziell für die globale Suche gelten und sich nur auf diese auswirken.
-
Katalog -> strPlatformSearchContentCatalog
-
Channels -> strPlatformSearchContentChannels
-
Kursvorlagen -> strPlatformSearchContentCourseTemplates
-
Mein Lernbereich -> strPlatformSearchContentLearningStatus
Die Standardbezeichnungen für die Plugins und Datenquellen lauten „imc-search-context-plugin“ für das Plugin „Mein Lernbereich“, „imc-search-catalog-plugin“ für das Katalog-Plugin und „imc-search-plugin-channels“ für das Channels-Plugin; sie können nicht geändert werden.
Leitlinien und Empfehlungen
Wir haben einige Tipps zur Nutzung der KI-gestützten Inhaltssuche zusammengestellt: