Die Funktion „Nutzerimport-Planung“ dient zur Konfiguration von Batch-Importaufträgen für CSV-Benutzerdateien und zum direkten Zugriff auf Importprotokolldateien in der GUI. Es können mehrere kundenspezifische Importaufträge konfiguriert werden, die entweder geplant oder manuell bearbeitet werden und möglicherweise auf die Erstellung und/oder Aktualisierung von Benutzern beschränkt sind.
Die Funktion „Nutzerimport-Planung“ ist über den Menüpfad „Admin > Nutzer > Nutzerverwaltung“ zugänglich, wo es zwei Registerkarten gibt: „Nutzerimporte“ und „Protokolldatei“.
-20260415-105128.jpeg?cb=03ec16de2da1674c9bae8159c1ee74ea)
Diese Funktion ist für die Verwendung durch Scheer imc-Berater vorgesehen, wird jedoch auch von vielen Kunden, die mit Batch-Datei-Schnittstellenprozessen vertraut sind, erfolgreich genutzt. In dieser Funktion können neue Importaufträge erstellt werden, bestehende Aufträge bearbeitet oder gelöscht werden und auf Nutzer-Importprotokolldateien zugriffen werden. Auf dieser Seite werden die Optionen ausführlich erläutert.
Funktionen der Nutzerimport-Planung
Wie erstelle ich einen neuen Nutzer-Import-Auftrag?
Das Erstellen eines neuen Benutzerimport-Auftrags ist ganz einfach, wenn die notwendigen persönlichen Attribute bereits konfiguriert sind. Um mit der Erstellung eines Imports zu beginnen, klicken Sie auf das Symbol „Erstellen“. Daraufhin öffnet sich ein neuer Browser-Tab. Für die Konfiguration von Benutzerimport-Aufträgen müssen neun Felder ausgefüllt und ein XML-Mapping-Datei-Upload erfolgen.
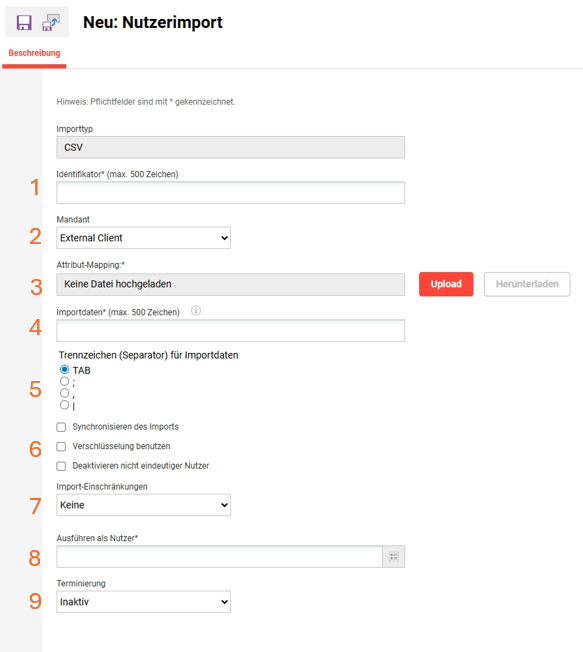
Jedes Feld und jede Einstellung auf der Registerkarte „Beschreibung“ wird im Folgenden beschrieben:
-
Identifikator: Dies ist der eindeutige Name des Importauftrags, jedoch nicht der Name der CSV-Datei.
-
Mandant: Es muss ein Mandant festgelegt werden, der zum „Stamm-Mandant” des importierten Benutzers wird, sofern in den Geschäftsregeln nichts anderes festgelegt ist. In einem Multi-Mandant-System wird der Benutzerimport auch nur für Benutzer innerhalb des Mandanten, der einen manuellen Benutzerimport in der Funktion „Nutzer“ durchführt, sichtbar sein.
-
Attribut-Mapping: Für dieses Upload-Feld ist die Erstellung einer XML-Datei notwendig, die im Wesentlichen die Spaltennamen der CSV-Datei den Namen der persönlichen Attributdatenbank zuordnet. Dies wird im Folgenden ausführlich erläutert.
-
Importdateien: Dies ist der Name der CSV-Datei, die verwendet werden soll, wenn der Importauftrag des Benutzers als „Täglich“, „Wöchentlich“ oder „Monatlich“ geplant wird. Wenn die Planung „Manuell“ ist, wird der Dateiname beim manuellen Importvorgang nicht erzwungen.
-
Trennzeichen für Importdaten: Hier kann das Spaltentrennzeichen/Trennzeichen entweder als TAB, Semikolon, Komma oder Pipe definiert werden, und die Datei muss beim Importieren übereinstimmen. Eine Pipe wird im Allgemeinen empfohlen, wenn das Quellsystem eine CSV-Datei mit diesem Trennzeichen generieren kann.
-
Checkbox:
-
Synchronisierung des Imports: Wenn diese Option aktiviert ist, werden bei nachfolgenden Importen alle zuvor importierten Benutzer, die nicht mehr in der Datei enthalten sind, automatisch deaktiviert. Die Synchronisierung wird in erster Linie in Fällen verwendet, in denen ein Quellsystem keinen Beendigungsstatus in einem Import senden kann, da nur „aktive” Datensätze bereitgestellt werden können. Viele Kunden verwenden diese Einstellung, sie muss jedoch mit Vorsicht verwendet werden, da schlecht generierte Teildateien unbeabsichtigt Benutzer deaktivieren können, wenn diese nicht in der Datei enthalten sind.
-
Verschlüsselung benutzen: Für zusätzliche Sicherheit können Benutzerimportdateien mit PGP-Verschlüsselung geschützt werden. Wenn diese Option aktiviert ist, muss eine verschlüsselte Datei übermittelt werden, die den in der Funktion „Konfiguration > Schlüsselverwaltung“ definierten Verschlüsselungseinstellungen entspricht.
-
Deakgtivierung nicht eindeutiger Nutzer: Legt fest, dass alle Nutzer, die zweimal in der CSV-Datei erwähnt werden, deaktiviert werden. Dies gilt nur für Nutzer, die mit demselben Import erstellt wurden (überprüfbar über das Nutzer-Attribut „Import-ID“).
-
-
Import-Einschränkungen: Importaufträge können auf „Nur einfügen“-Nutzer oder „nur aktualisieren“-Nutzer beschränkt werden. Der Standardwert „Keine“ bedeutet, dass keine Beschränkung aktiv ist, sodass der Importauftrag sowohl neue Benutzerdatensätze erstellen als auch bestehende aktualisieren kann.
-
Ausführen als Nutzer: Ermöglicht die Auswahl eines Benutzers im LMS, in dessen Namen der Import bearbeitet und Importprotokolldateien gesendet werden.
-
Terminierung: Eine einzelne Auswahloption, die festlegt, wie und wann der Importauftrag verarbeitet wird.
-
Inaktiv: Die Verfügbarkeit des Importauftrags ist weder für manuelle noch für automatische Aufträge gegeben.
-
Manuell: Kann beim Importieren in der GUI über das Menü „Nutzer“ als verfügbarer Import ausgewählt werden.
-
Täglich: Der Importvorgang wird täglich zu der im CRON festgelegten Zeit ausgeführt, und die CSV-Datei ist zuvor auf einen SFTP-Server hochzuladen.
-
Wöchentlich: Der Importvorgang wird wöchentlich zu der im CRON festgelegten Zeit ausgeführt, und die CSV-Datei ist es notwendig, zuvor auf einen SFTP-Server geladen zu werden.
-
Monatlich: Der Importvorgang wird monatlich zu dem im CRON festgelegten Zeitpunkt durchgeführt, und es ist notwendig, die CSV-Datei zuvor auf einen SFTP-Server hochzuladen.
-
Wie erstellt man eine XML-Import-Zuordnungsdatei?
Die .xml-Zuordnungsdatei wird verwendet, um die Struktur der .csv-Datei zu definieren, einschließlich der Zuordnung von Spaltennamen zu Namen in der Datenbank für persönliche Attribute. Die Benutzerimportdatei muss mindestens die obligatorischen persönlichen Attribute in LMS enthalten, wie unten gezeigt, aber die Anzahl der Spalten, die persönlichen Attributen zugeordnet sind, ist normalerweise viel höher. Um einen neuen Nutzer anzulegen, müssen die folgenden obligatorischen Standardattribute im System enthalten sein:
-
LOGIN (Generator kann verwendet werden)
-
VORNAME
-
NACHNAME
-
E-MAIL
-
EXT_ID_CSV (obligatorische eindeutige Kennung für CSV-Importe)
Es gibt viele Tools zum Erstellen von XML-Dateien, darunter das frei verfügbare Notepad++. Das Format einer einfachen XML-Zuordnungsdatei, die die oben genannten obligatorischen Attribute enthält, würde wie folgt aussehen:
<CSV>
<attributzuordnung>
<mappingsourceField="Benutzername" clixField="LOGIN"/>
<MAPPING sourceField="Vorname" clixField="FIRSTNAME"/>
<mapping sourceField="Nachname" clixField="LASTNAME"/>
<MAPPING sourceField="E-Mail" clixField="EMAIL"/>
<mapping sourceField="ID" clixField="EXT_ID_CSV"/>
</attributeMapping>
</CSV>
Hinweis: Das <CSV>-Tag wird nur benötigt, wenn die .xml-Datei direkt während eines Imports in der Funktion „Nutzer” hochgeladen wird, da benutzerdefinierte Zuordnungen zum Zeitpunkt des manuellen Imports hochgeladen werden können. Wenn die Zuordnungsdatei gemäß diesem Beispiel in der Nutzerimport-Planung hochgeladen wird, wird das CSV-Tag tatsächlich automatisch anhand der angegebenen Einstellungen generiert.
Fortgeschrittene Mappingeinstellungen
Die .xml-Zuordnung kann einige fortgeschrittene Funktionen unterstützen, wie zum Beispiel:
-
Ignoriere nicht zugeordnete Felder - Ignoriert alle Spalten in der CSV-Datei, die nicht zugeordnet sind.
-
Leeres Feld ignorieren - Konfiguriert pro Zuordnungszeile, wobei „false“ einen ausgefüllten Wert durch ein Leerzeichen überschreiben kann und „true“ einen ausgefüllten Wert nicht durch ein Leerzeichen überschreibt.
-
Hashident - Bezieht sich auf einen Hash-Tabellen-Identifikator, bei dem es sich um eine Konvertierungstabelle in den Registrierungsgeschäftsregeln (siehe unten) handelt. Wird häufig für den Import anhand von Auswahllisten verwendet, um diese anstelle der Scheer imc-ID oder mit Datumsfeldformatkonvertierungen zu verwenden.
Ein Beispiel für eine komplexere Tabelle finden Sie unten:
<attributeMapping ignoreUnmappedFields="true">
<mappingsourceField="Benutzername" clixField="LOGIN"/>
<MAPPING sourceField="Vorname" clixField="FIRSTNAME"/>
<mapping sourceField="Nachname" clixField="LASTNAME"/>
<MAPPING sourceField="E-Mail" clixField="EMAIL"/>
<mapping sourceField="ID" clixField="EXT_ID_CSV"/>
<MAPPING sourceField="Zugangsvoraussetzungen" clixField="ACCESS_REQ" ignoreEmptyField="false"/>
<MAPPING sourceField="Stelle" clixField="POSITION" hashident="POSITIONHASHTABLE"/>
</attributeMapping>
Wie ist die SFTP-Einrichtung?
Wenn Importaufträge so geplant sind, dass sie täglich, wöchentlich oder monatlich automatisch verarbeitet werden, ist es notwendig, dass ein Scheer imc-Berater den Zugriff auf einen von Scheer imc bereitgestellten SFTP-Server organisiert. Der Kunde ist dann dafür verantwortlich, die vereinbarte CSV-Datei zum vereinbarten Zeitpunkt hochzuladen, und ein Transferauftrag überträgt die Datei vom SFTP-Server an einen bestimmten Standort auf dem LMS-Inhaltsserver (z. B. \data\person\personimport\src\staff). Der SFTP-Server wird vom Hosting-Team (ECMT) von Scheer imc verwaltet, da aus Sicherheitsgründen kein direkter Zugriff auf die von Scheer imc gehosteten LMS-Server möglich ist. Das Hosting-Team von Scheer imc stellt den Kunden eindeutige Anmeldedaten für den Zugriff auf ihr SFTP-Konto zur Verfügung. Der Zugriff kann falls notwendig durch eine IP-Whitelist eingeschränkt werden.
Was ist ein Cron-Job und wie wird er konfiguriert?
Ein Cron-Job ist ein automatischer, zeitgesteuerter Job, der so konfiguriert werden kann, dass er zu gewünschten Zeiten ausgeführt wird. Im LMS stehen viele Cron-Jobs zur Verfügung, darunter „UserImport“. Die Cron-Jobs wurden traditionell von Scheer imc-Beratern programmiert. Ab 2022 besteht die Möglichkeit, sie über eine neue Funktion „Cron-Jobs“ direkt in der GUI zu konfigurieren. Bei der Cron-Konfiguration ist die zeitliche Abfolge der Aufgaben wichtig, um sicherzustellen, dass die Daten so aktuell wie möglich sind. So muss beispielsweise der Cron „UserImport“ nach der Übertragung der Datei durch SFTP ausgeführt werden und sollte vor den Aufgaben „TargetGroupPersonAssignment“ und „ParticipantAutomaticRegistration“ ausgeführt werden. Bei Cron-Jobs verwendet Scheer imc den Quartz-Cron-Standard. Die Datums-/Zeitformate sind hier beschrieben: https://www.freeformatter.com/cron-expression-generator-quartz.html. Im folgenden Beispiel würde der Import täglich um 23 Uhr ausgeführt werden.

Können CSV-Dateien verschlüsselt werden?
Für CSV-Nutzerimportdateien unterstützt Scheer imc die Verwendung von PGP-Verschlüsselung, wobei Kunden verschlüsselte Dateien für zusätzliche Sicherheit auf den SFTP-Server laden können. Der Kunde ist für den privaten Schlüssel verantwortlich und muss Scheer imc einen öffentlichen Schlüssel mitteilen, mit dem die Dateien zum Zeitpunkt des Imports entschlüsselt werden können. Diese Aufgaben können von Scheer imc-Beratern ab ILS 14.13 konfiguriert werden und können kundenspezifisch sein, sodass nicht jeder Benutzerimportjob davon betroffen ist.
Was sind Registrierungs-/Geschäftsregeln?
Wenn Nutzer entweder lokal (in der GUI) oder durch Import erstellt oder aktualisiert werden, wird eine Reihe von Geschäftsregeln ausgelöst. Die Regeln werden von Scheer imc-Beratern in XML-Code geschrieben, um auf der Grundlage persönlicher Attributwerte verschiedene Aufgaben auszuführen. Dazu gehören die Zuweisung von Benutzern zu Gruppen (Rollen oder Geschäftsbereichen) oder Mandanten, die Zuweisung von Jobprofilen, die Erteilung von Freigaben für Benutzer in Administratorengruppen, die Eingabe von Einstellungen wie Spracheinstellungen oder Zeitzonen, die Festlegung des Authentifizierungsstatus und andere fortgeschrittenere Regeln wie Konvertierungen. In der Regel werden Geschäftsregeln von Beratern während der Implementierungsprojekte geschrieben, können aber jederzeit direkt in der GUI aktualisiert werden, entweder global für alle Kunden (Konfiguration) oder mandantenspezifisch (Mandant).
Wie kann man auf Nutzerimport-Protokolldateien zugreifen und diese interpretieren?
Logdateien werden normalerweise automatisch per E-Mail an den implementierten Benutzer gesendet, wenn ein Import erfolgreich beendet ist. Sie können jedoch auch direkt in der Funktion „Nutzerimport-Planung” auf der Registerkarte „Logdatei” aufgerufen werden. Hier wird für jeden Import eine praktische Zusammenfassung in chronologischer Reihenfolge angezeigt, die wichtige Übersichtsinformationen wie Status, Anzahl der Datensätze und vor allem die Anzahl der zu bearbeitenden fehlerhaften Datensätze enthält.

Eine detaillierte CSV-Protokolldatei kann heruntergeladen werden, indem Sie das gewünschte Importdatum markieren und auf die Schaltfläche „Herunterladen“ klicken, um eine ZIP-Datei mit der Importprotokolldatei herunterzuladen. Beim Öffnen der CSV-Datei in der ZIP-Datei wird erneut eine zusammenfassende Übersicht angezeigt. Weiter unten befindet sich eine Zeile für jeden Benutzerdatensatz, der in der Benutzerdatendatei enthalten ist, mit einem Importstatus.
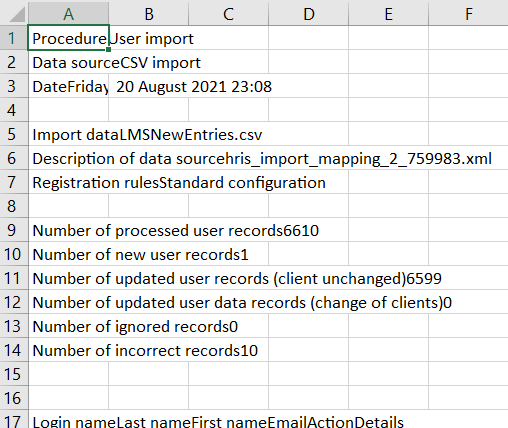
Wenn Fehler auftreten, verwenden Sie „Strg + F“ und suchen Sie nach dem Wort „Fehler“, um alle Datensätze zu finden, die nicht importiert wurden. Klicken Sie dann in jeder betroffenen Zeile auf die Spalte, um die Beschreibung jedes Fehlers einschließlich des Fehlercodes anzuzeigen. Die häufigsten Fehler stehen in der Regel im Zusammenhang mit Login-Konflikten, fehlenden Pflichtattributen wie E-Mail, falschen E-Mail-Formaten, falschen Datumsformaten (falls Datumsattribute vorhanden sind) und duplizierten Einträgen in der Spalte EXT_ID_CSV. Eine Beispielfehlermeldung für ein doppeltes Login lautet: „Fehler, leider ist der von Ihnen eingegebene Login-Name bereits einem anderen Benutzer zugewiesen. Bitte wählen Sie einen anderen Login-Namen. [Fehlercode:PRS0126]”.
Tipps zum Troubleshooting bei Importfehlern
-
Überprüfen Sie, ob die notwendigen Attribute in der Zuordnung und der CSV-Datei enthalten sind.
-
Überprüfen Sie die Codierung und den Feldtrennzeichen, die in mapping.xml definiert sind, sowie die in der CSV-Datei angewendeten Einstellungen.
-
Überprüfen Sie die Spaltennamen und die Namen der Attribute, die in der Datei „mapping.xml“, der CSV-Datei und im LMS der imc Learning Suite definiert sind.
-
Überprüfen Sie die Registrierungsregeln und die korrekte Schreibweise von Attribut-Namen und gegebenenfalls Hashtable-Referenzen.
Tipps & Tricks
-
Für die Konfiguration komplexer Importe, einschließlich solcher, die Geschäftsregeln und automatische Zeitplanung notwendig machen, wenden Sie sich bitte an das Scheer imc Consulting Team.
-
Wenn Sie einen geplanten Import verwenden, der nicht synchronisiert ist, kann es sinnvoll sein, einen manuellen Import mit denselben Zuordnungen und Einstellungen durchzuführen. Dies ist ideal für Testzwecke und als Notfallmaßnahme für den Fall, dass der geplante Import aus irgendeinem Grund nicht durchgeführt wird.
-
Bei Verwendung eines Komma-Trennzeichens/Begrenzungszeichens ist das Risiko, dass ein Komma innerhalb eines Werts vorkommt, oft recht hoch. In diesem Fall kann das Komma in Anführungszeichen gesetzt werden, um eine fehlerhafte Spaltenbearbeitung zu vermeiden.
-
Wenn Logik so konzipiert werden kann, dass eine Aufgabe auf der Grundlage von Attributdaten erfolgreich beendet wird, könnte es möglich sein, eine Registrierungs-/Geschäftsregel zu schreiben. In solchen Fällen wenden Sie sich am besten an einen erfahrenen Scheer imc-Berater, indem Sie ein Support-Ticket des Level 2 einreichen.