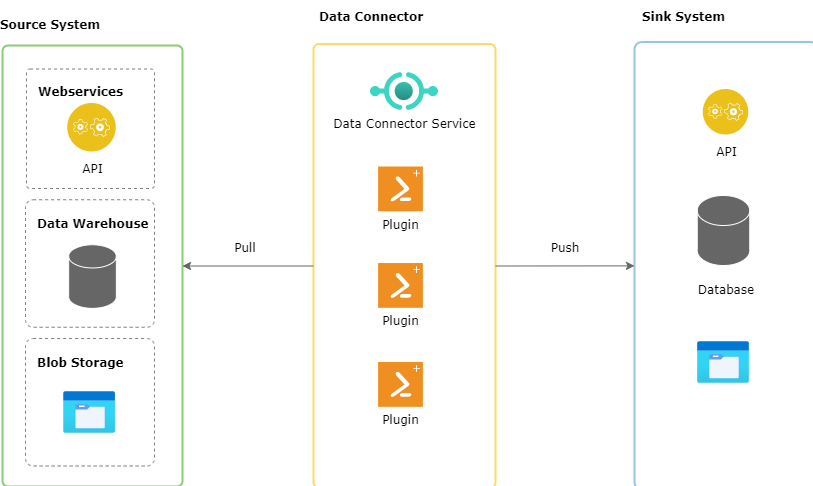
“Data Connector” serves as a bridge between various data sources and target systems, automating the extraction and transfer of data through the use of plugins. They can either push or pull data from a source system to a target system. Their core functions include fetching, aggregating, transforming, and transferring data between systems.
The “Data Connector” allows you to manage which content areas (data sources) are included for indexing in the global search, as well as define when the data should be indexed.
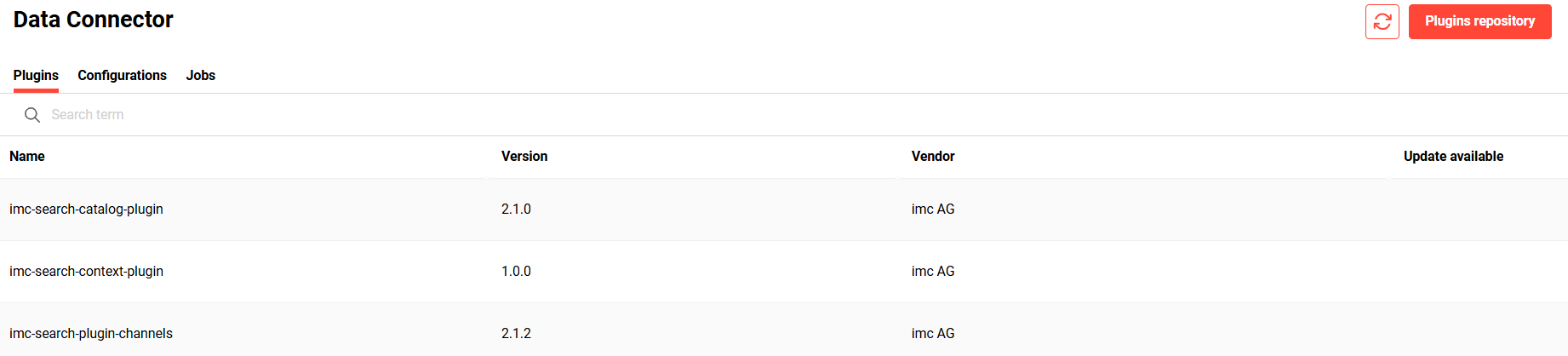
To enable this, the “Data Connector” provides three tabs for managing plugins, configurations and jobs.
Tab “Plugins”
A Data Connector plugin connect to its designated source system, fetch data, transform it if necessary and pushes that to its defined sink system - similar to pure ETL processes.
Here admins can manage the content areas considered for indexing for AI-enhanced content search. The content from only these content areas are available for searching by the learner.
Currently catalogue, channels (only if channel license is active) and “My learning” are provided as three content areas as standard offering and configured by default. Additional content areas / data sources can be added by requesting imc.
This tab allows users to
-
install plugins from the plugin repository
-
update an already installed plugin if a new version is available
Content accessible in search results
Following settings influence which content is seen from each plugins by the user.
Settings considered for indexing catalogue plugin
-
Learner only sees the content (Courses, Course templates, Learning paths, Learning paths templates, Medias) in search results from those catalogues where they have been directly assigned and these catalogues are accessible in the personal ILP navigation of the learner and have “Catalogue->Do not show catalogue in front end” disabled.
-
Learner only sees the content in search results which
-
have the type configured in “Catalogues->Displayed object types” and
-
are displayable as defined by the metatag “Display in catalogue until” and
-
have planning status “Released” or “Fixed”
-
-
Indirectly assigned courses are shown in the search results if the following settings are active:
-
Configuration->Catalog->Display of courses from templates based on clearances and
-
Client->Catalogue settings->Show indirectly assigned courses in the catalogue or “Show indirectly assigned courses when using free text search” and
-
Course->Metatag - Viewable via template
-
-
If Client->Catalogue settings->“Take into account the clearances for the display of catalogue content” is active, only if the user has minimum view clearances to the content, then this content is shown in the search results.
Settings considered for indexing channel plugin
User should have minimum of view rights for a channel to view the content (Medias) of that channel in search results.
Please note channels itself are not shown in the search results.
Settings considered for indexing “My learning” plugin
Only the content (Courses, Course templates, Learning paths, Learning paths templates) which is accessible to the user via “My learning” according to the settings defined in Configuration manager and Client settings is shown in the search results.
If a content has been assigned to catalogue and has a status on it, it would still show “My Learning” as one of the parents on the search tile for the content even though it has been defined in the Learning Area settings that the content with this status should not be shown in “My learning”.
Plugin repository
Plugin repository shows the plugins available for installation.

Following information related to a plugin is displayed:
-
Name of the plugin
-
Version of the plugin
-
Vendor of the plugin
-
Description of the plugin
Editing a plugin configuration
Currently the configurations for catalogue, channels (only if channel license is active) and “My learning” are provided by default.
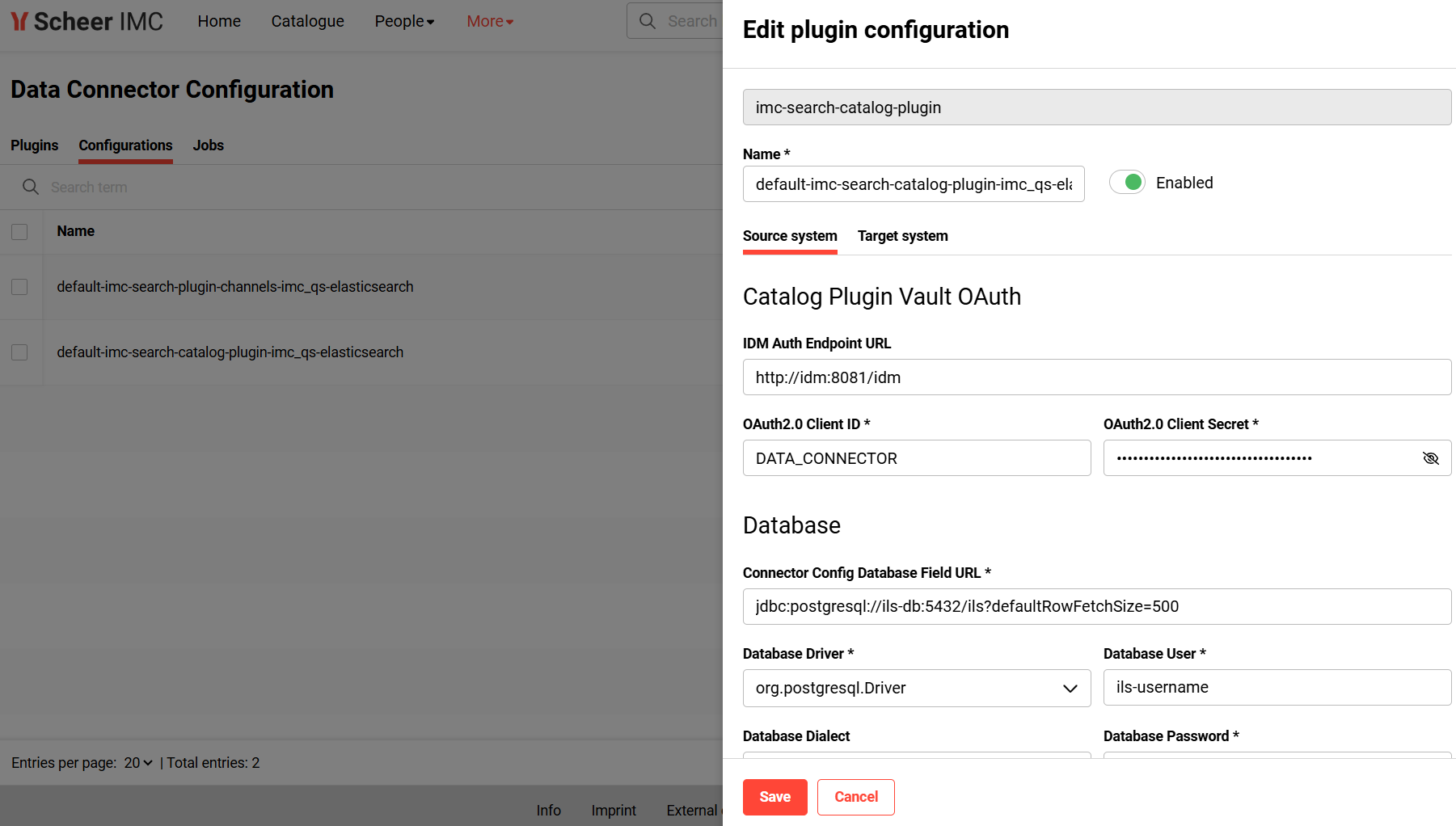
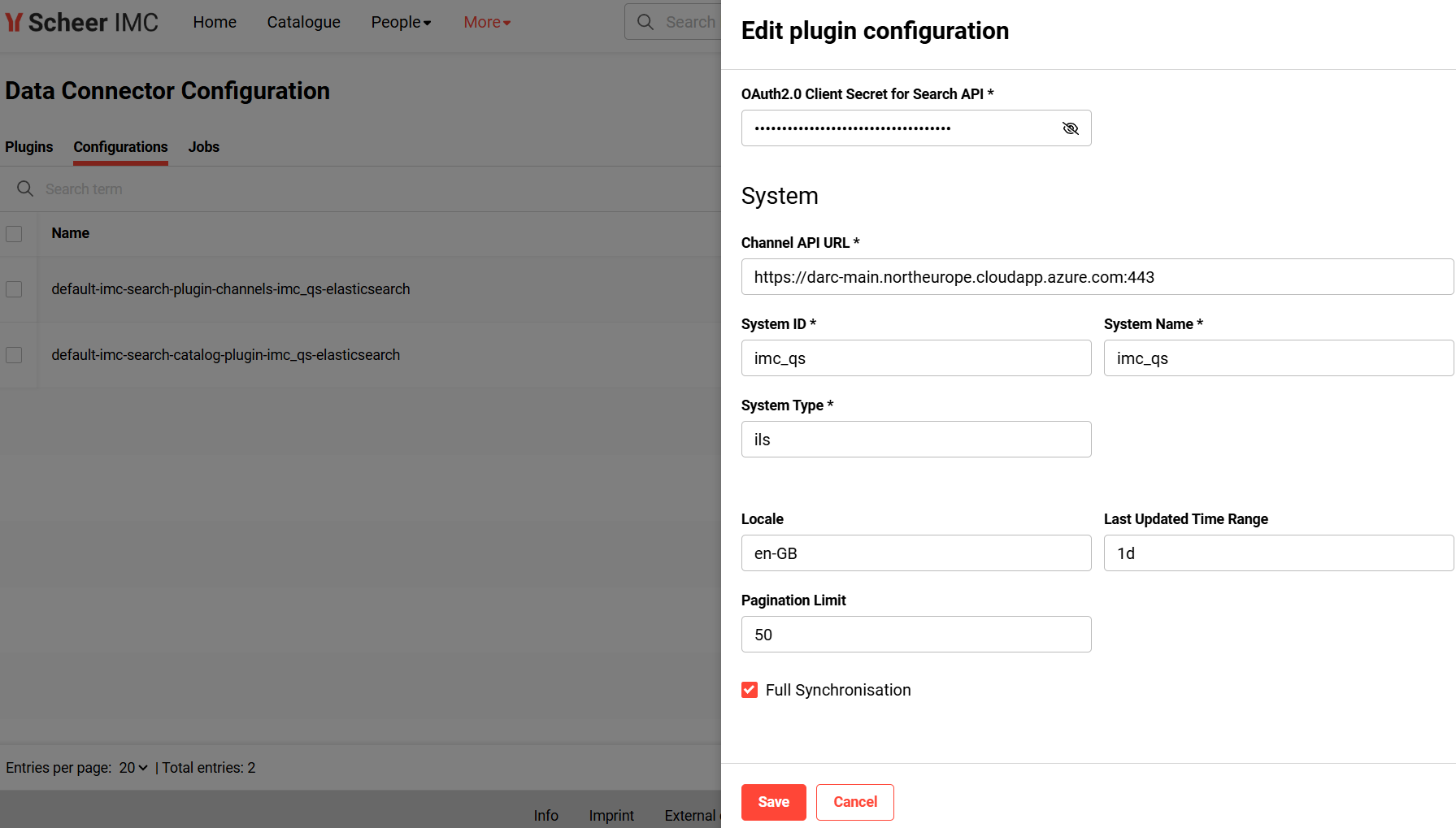
This function enables the administrator to edit a plugin configuration. A plugin configuration represents properties that must or can be configured.
A Data Connector plugin is executed as asynchronous job based on its schedule and plugin configuration.
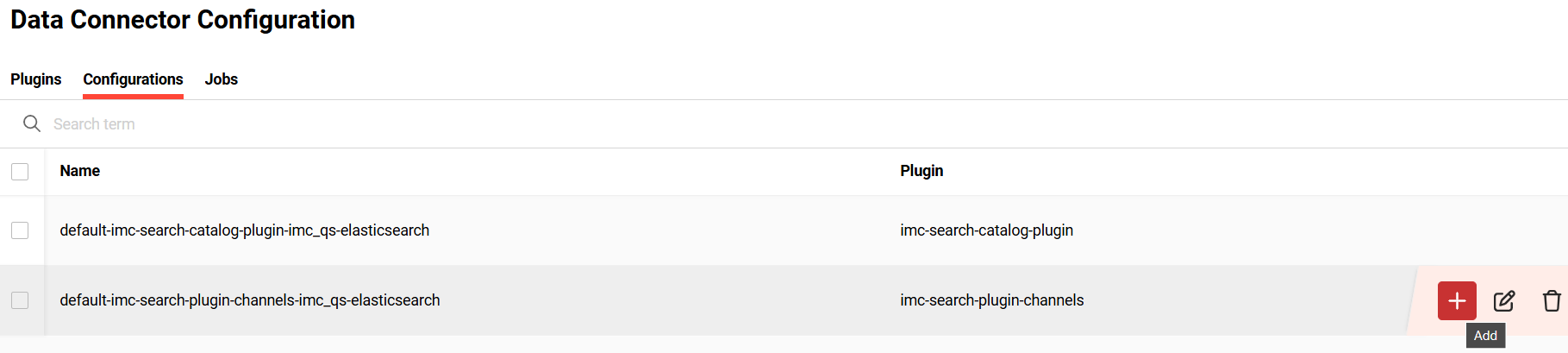
Configurations
Plugin Configuration helps to define configuration parameters required for the source and sink system.
By default, jobs have already been scheduled for the catalogue, channels (only if license is available) and “My learning” to run daily in the night. The job for channel plugin has been scheduled to run at 9 p.m. server time, catalogue plugin at 10 p.m. server time and “My learning” plugin at 11 p.m. server time. Please note the user interface shows the regional time zone. Hence it might show a different time than 9 p.m. or 10 p.m. depending on your location. If you want to ensure that the jobs run according to your regional time zone please update the jobs accordingly.
Configurations tab allows an admin to do the following functions:
-
add a scheduled job. This function is only available if a job has not already been added for the selected configuration. The job can be scheduled either one-time, daily or with a cron job expression (e.g. */15 * * * * to schedule every 15 minutes). Please refer to https://en.wikipedia.org/wiki/Cron for more details on cron job expression.
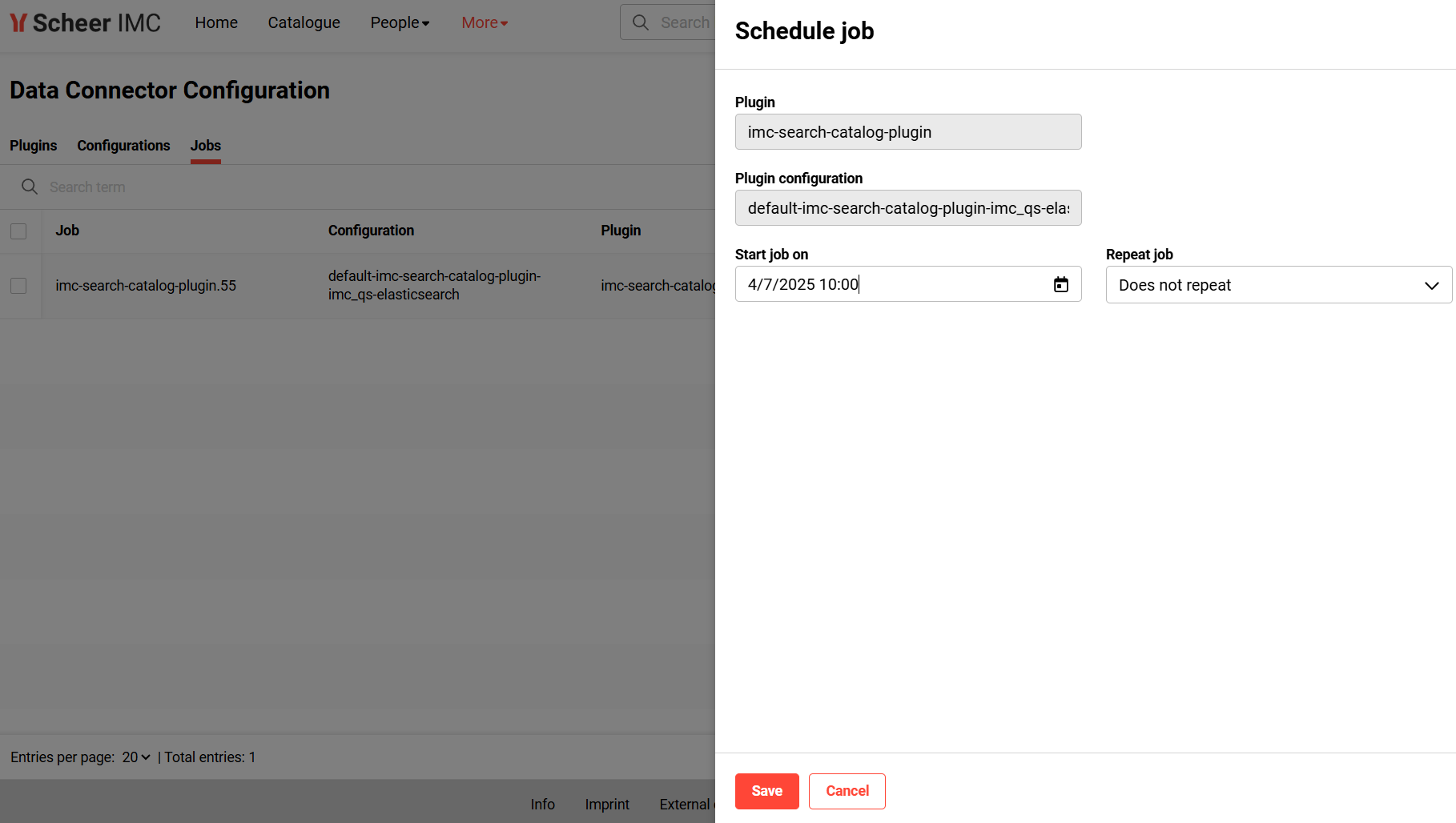
-
edit a plugin configuration. In case a job has been already scheduled for an existing plugin configuration, the job will be updated with the recent changes. For jobs currently executed while updating a configuration, the modification takes effect only with the next execution.
-
delete a plugin configuration. Scheduled jobs will be deleted as well. In case a job is currently executing, that job will nevertheless run to completion.
Plugin and configuration is automatically created for channels, catalogues and “My learning”. Hence it is recommended not to edit/delete them.
For channels, by default, the service account user in the channels plugin configuration has been set to noreplysuper@im-c.de. If automatic scheduling of channel plugin job fails, it is important to enter a valid super user’s email address as the service account user so that the channels plugin has access to the channels microservice.

Full-indexing
After the switch of the semantic to lexical search or vice-versa, full-indexing is required for all the plugin configurations to take effect for the user. Please note the full-indexing might take a lot of time depending on the size of the data to be indexed. So it is recommended to run the job in the night.
To do full-indexing of the catalogue plugin, edit the plugin configuration and set the property “Number of days to sync back” to 0 (already the default).

To do full-indexing of the channel plugin, edit the plugin configuration and enable the property “Full Synchronisation”.
Jobs
Jobs tab allows an admin to manage the jobs for catalogues, channels and “My learning” plugins.
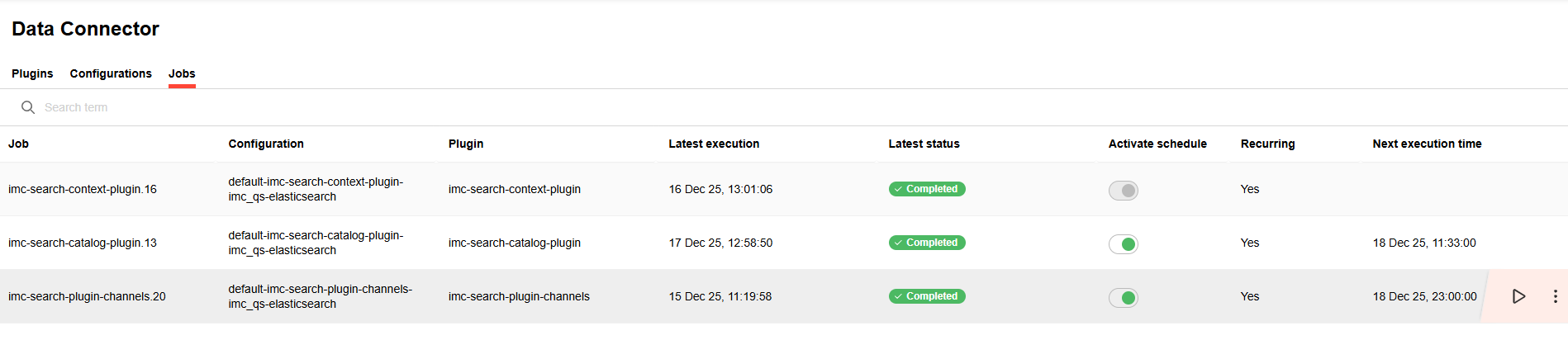
Following functions are supported.
Execute

User can trigger a job to run instantly by clicking on the “Execute now” button.
Edit
User can edit a job with the help of “Edit button”.
Activate schedule
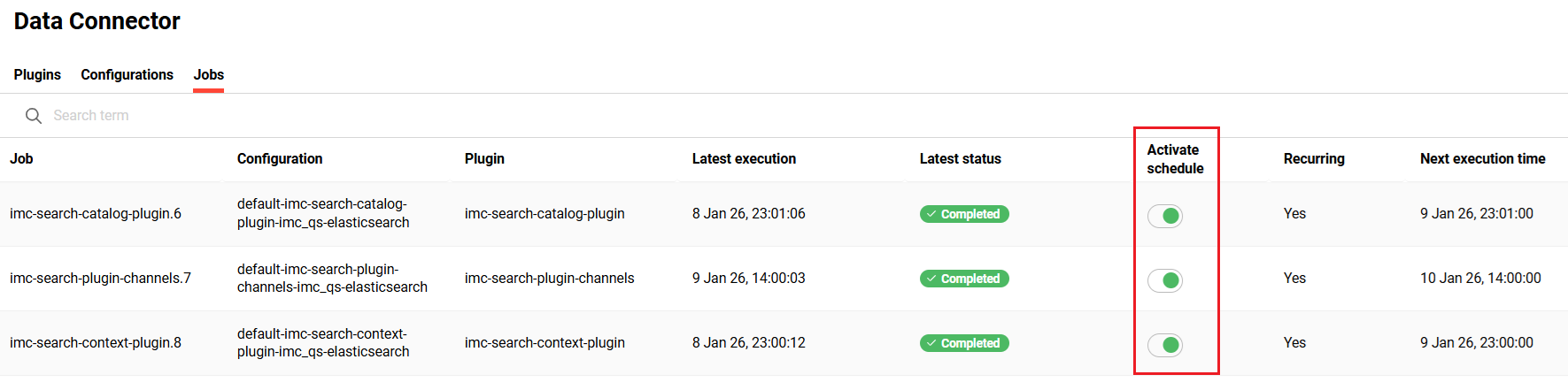
-
pause a scheduled job via the “activate schedule” toggle
-
resume a scheduled job via the “activate schedule” toggle
Delete

-
delete a scheduled job
Download
-
download log file to check errors for failed jobs